The term “database” is widely used in different contexts in the digital world. Since I started my career, I’ve seen this term referring to different things: Excel spreadsheets, tables on websites, text files, and other formats. Indeed, all these things can be considered databases, at least according to Wikipedia’s definition:
…a database is an organized collection of data stored and accessed electronically.
This definition from Wikipedia sounds simple. It can be said that a text file containing my name and phone number is a database. However, this is very fragile—what if the file is deleted or corrupted? What if I add some information there that doesn’t belong? When developing a real-world application, we need a robust system to manage our data.

Databases are the most important part of any software system. After all, this is where all the information of an application is stored, such as user names, email, address and even passwords (hopefully cryptographically hashed). But how is a database system better than a text file? This article gives an overview and introduction to the concept of databases in the context of software development.
Database Management Systems
DBMS are special pieces of software designed to manage the storage of data in a computer system. They can read, write, remove or edit data, in addition to controlling access to the information and other features. Everyone who works with software development will eventually deal with a DBMS, so it is important to understand how they work, at least superficially. Some of the most widely used DBMS software today are MySQL, PostgreSQL and MongoDB. I became interested in databases when I learned to manage my data using a DBMS simply by writing SQL queries, and I was curious to know what was happening inside the DBMS.
The DBMS is a mediator with which the user can manage data reliably. It can be accessed through a graphic interface client, through the command line in a terminal, or through an application’s code, where typically queries are created and sent for a DBMS to execute in a database.
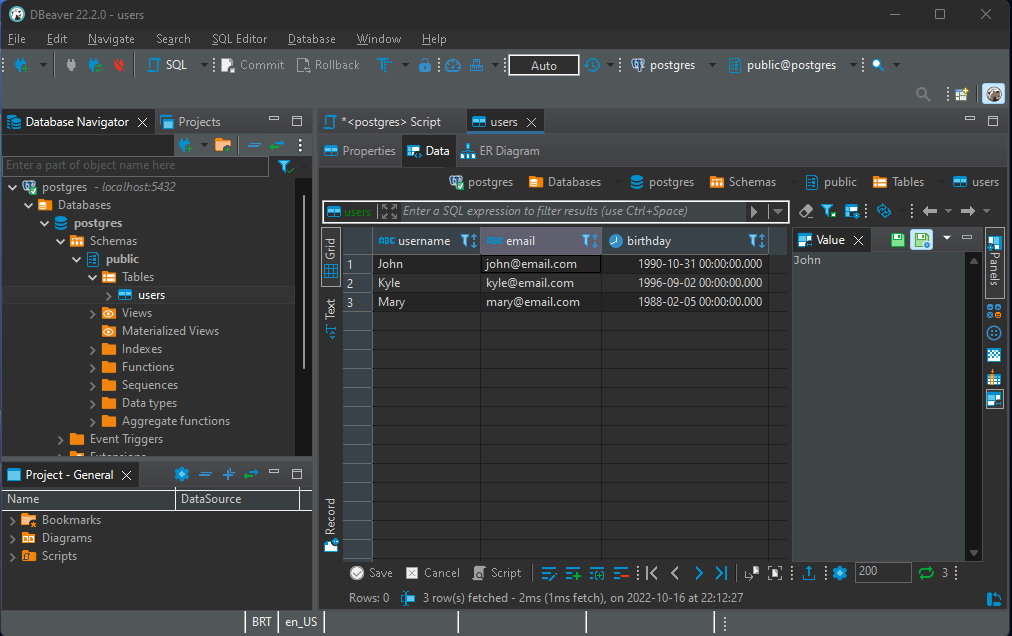
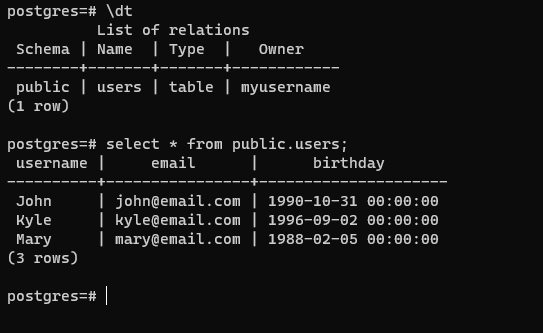
The most common case you will find as a developer is accessing a DBMS through an application’s code. This example below shows JavaScript objects being used to access the same PostgreSQL database using sequelize, an Object Relational-Mapping library.
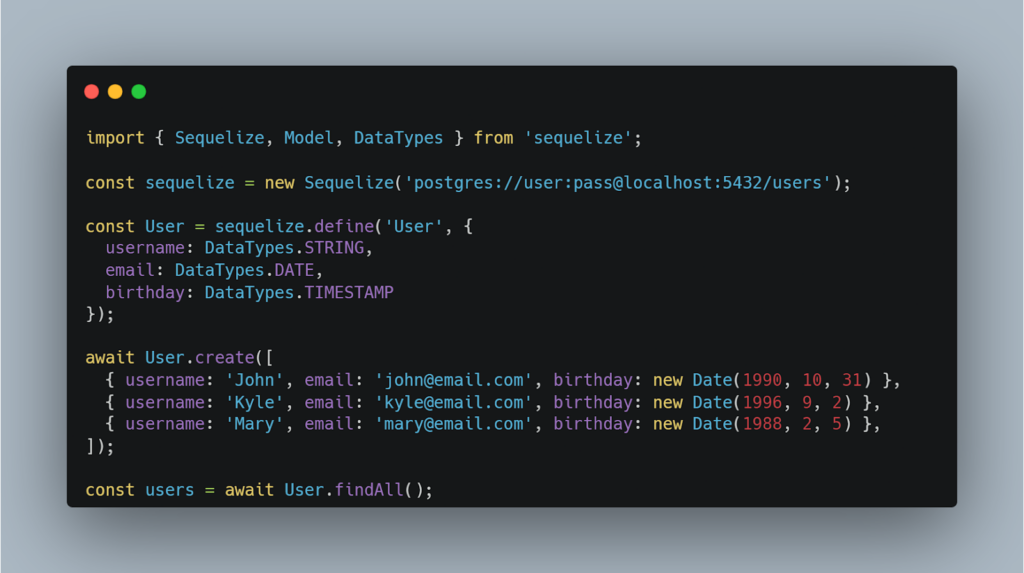
Those systems behave much like a server responding to client requests. They get a query from the client and respond with data, or an error message in case there were a problem with the query or with the DBMS itself. The query comes from the client as a string, which is parsed, and then executed by the DBMS. Database servers can run on the same machine as the application calling them, or on a different machine on the same network. They can even run on a distant computer in the cloud.
Types of databases
The description given before applies to pretty much all database systems, and there are lots of them today. Each flavor of database has its own pros and cons, being used for different types of features and applications depending on the user’s needs. They are typically separated in two categories: relational and non-relational.
The relational database model emerged in the 1960s, and is the most used to date. In this model, data is stored in tables that contain rows and columns. Each row is an entry, or an observation, and each column is a field, or an attribute of that data entry. This helps to avoid duplicate information and makes it easier to create relationships between different tables.
Queries for relational databases are normally built with a Structured Query Language—SQL, that allows you to specify exactly the data you want, in the format that you want. If you work with software development, it is more than likely that you had to work with SQL, or at least some type of abstraction to it like an ORM (Object–relational mapping) that allows you to make queries from your code without having to write SQL statements.
Non-relational databases are normally referred to as NoSQL—not only SQL, and they are hard to define. They encompass various types of databases that don’t fit in with the relational model. It’s possible to write a whole article about NoSQL databases and all their different types. Some of the most famous members of this class are MongoDB and Redis. It is not in the scope of this article to explore all types of databases, but the principles explained here apply to most of them.
NoSQL databases are more flexible in the way they store data. In the relational model, you have to respect all the constraints and rules of your schema, which is basically the structure of your tables and columns. Most non-relational databases allow you to store data in any way you want, for example MongoDB can store your data in collections of documents, that are basically JSON objects. Redis on the other hand is a key-value store, where you save just keys and their values, looking to optimize space and performance.
Transactions and their properties
A database transaction is a unit of work that is composed of a collection of queries that have a logical reason to be together. For example, consider a money transfer between two people. We need to have the amount of the transfer subtracted from the sender’s balance—if there is enough money—and added to the receiver’s balance. This pair of operations constitutes one transaction.
To guarantee the validity of the data being recorded, database transactions should be compliant with the ACID properties.
- Atomicity defines that transactions need to happen completely, or not at all. This is especially critical in systems that deal with financial data, like in our bank account example—if this money transfer transaction breaks after subtracting the sender’s balance and before adding to the receiver’s, we lose track of money. After a transaction starts, if everything runs correctly it will commit the changes, meaning that they will all be written to disk permanently. If anything goes wrong, it will rollback and none of the changes made by the transaction are persisted.
- Consistency ensures that the data stored in the database is actually correct, meaning that it guarantees referential integrity and all other rules applied to a database system, so the information registered there makes sense. For instance, in the bank account example, you cannot have a money transfer to a user that is not on your users table.
- Isolation guarantees that all database transactions happen independently of each other. This is especially important in systems where there are a lot of simultaneous queries hitting the database. The DBMS cannot allow that the changes of an uncommitted transaction interfere with another one.
- Durability is the property that guarantees that the data, after a transaction is committed, is actually persisted to disk and will be available even after a system crash. This is a more complex topic and involves knowledge in hardware and other topics, but the general idea is straightforward.
There are a number of problems that can happen if transactions don’t follow those properties, like incorrect reads, interference between separate transactions and even the loss of data. Most database systems nowadays have these properties natively implemented and have features that guarantee those properties. This is a vast topic to cover in just a few paragraphs, so I encourage you to do more research if it interests you.
Indexes and how they can improve performance
Much like the index of a book that tells you where the content you want to find is located, a database index stores the memory addresses of your data in an efficient manner, so it can handle searches much faster. When you index a database column, its data is stored in a separate space in the disk, according to a different data structure.
We need indexes when our databases grow too big, and searching them becomes slow. This is an algorithmic problem. Imagine if a database had to scan all its entries to determine the largest value of a column, for example. If there are billions of records, that can take a lot of time. In essence, indexes narrow down the space where you search for your data, so your DBMS can get what you want from a smaller set of query results.
Indexes normally convert rows in a table into nodes in a binary search tree. If you are familiar with computer science, you know that BSTs are a data structure where searching has a time complexity of O(log n), which is much faster than the O(n) complexity that comes with a simple, sequential search.
If you want to learn more about binary search trees, algorithmic time complexity, database transactions and much more, check out Computer Science Distilled. It will give you the fundamental concepts to understand computer science and make you a much more efficient coder. Besides, it is a fun and interesting read.
Like everything in software development, there is always a trade-off. We shouldn’t just index all our columns and hope our database will be super fast. Every new entry on a table requires its index to be updated as well, and that can be computationally expensive, so inserting an entry becomes a slower operation in the end. Besides that, indexes occupy additional disk space, which can pose an extra cost to your application.
There are also a few situations where adding an index might be useless. One example is when the indexed column has a lot of repeated values, for instance a nationality column in a users table of a service that is mostly used by customers from a single country, let’s say Brazil. If almost all of the users are Brazilian, the index won’t do much in terms of narrowing down your search space, since the database will have to do a non-indexed search among all those rows where nationality equals Brazilian, which will be practically the entire column. However, if you query for users from other countries, then this index is useful, because it will narrow down your search to the few non-Brazilian users there.
Likewise, an index is useless when you make some sort of change in the entire indexed column right before querying it. For example, searching for a value in a name column right after you apply an uppercase function to all the names. If the index was created on a lowercase name column, then this query will basically skip the index and do a regular search for uppercase values. This happens because the index stores the data it was told to, and a lowercase string is different data in memory than an uppercase string, even if they are the same word. It can also happen with the CAST statement in SQL, that converts the type of an entire column. Those kinds of statements force what is called a table scan, where the whole column is processed and transformed into something else that the index won’t recognize.
Only create indexes for the columns where you need them. Each index can make the read queries faster, while making insert, update and delete queries slower. As a software developer, it is your job to figure out which tables and columns are worth indexing. This is a critical part of database design, and a bad indexing strategy can significantly impact your application’s performance.
Conclusion
The topic of databases is incredibly vast and complex. This article was a brief introduction to someone who might know a little bit about SQL and databases but wants to explore some more.
Databases are powerful tools and a fundamental part of every application. Knowing how they work is key to having a healthy, performatic software that can serve users quickly. A bad decision on indexing strategies or transaction management can make your application slower or even worse, corrupt your data and negatively impact your project.
It is the programmer’s job to decide how and when to use each type of database system that best fits the needs of their application. It is important to know what problems you are trying to solve, so you can pick the best tool for the job.